
high availability چیست و چه کاربردی دارد؟
High availability یا دسترسی سطح بالا (HA) به توانایی یک سیستم برای فعالیت در بازه زمانی طولانیمدت گفته میشود. در برخی سازمانها و صنایع مختلف باید طبق نیاز و سطح عملکردی توافق شده یک سیستم یا سرویس در دسترس باشد که تحقق این امر بهوسیله HA برآورده میشود.
صنایع زیادی وجود دارند که دسترسی و عملکرد بهینه سرویسهای آنها حیاتی است و در صورت انجام نشدن آن امکان به خطر افتادن جان انسانها و حتی امنیت یک کشور وجود دارد. برای مثال اتومبیلهای خودران، صنایع دفاعی و صنایع پزشکی از جمله این موارد هستند. در این مقاله قصد داریم تا بهصورت کامل به بررسی موضوع ذکر شده بپردازیم، پس تا انتهای آن همراه باشید.
High availability یا دسترسی سطح بالا چیست؟
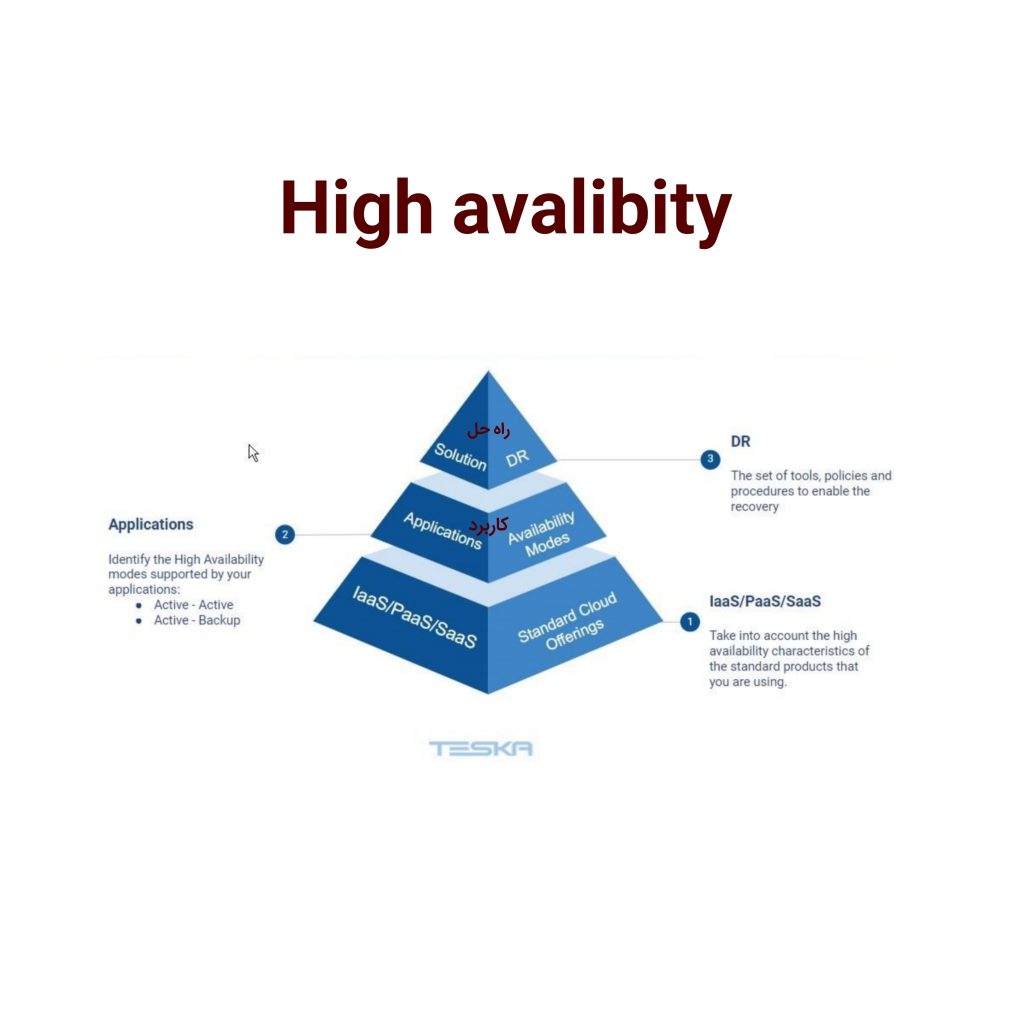
HA مخفف High availability است که در زبان فارسی میتوان آن را به معنای دسترسی در سطح بالا و نزدیک به مطلوبترین حالت مورد انتظار (99.999 یا پنج تا 9 درصد) ترجمه کرد. حال منظور از دسترسی چیست؟ دسترسی میتواند معنای استفاده از یک سیستمعامل مانند ویندوز یا لینوکس باشد، یا استفاده از برق در یک ساختمان و سازه به معنای دسترسی به انرژی برق در آنجا است. پس منظور از دسترسی یا availability قادر بودن به استفاده از یک سیستم، سرویس، انرژی، محصول و هر چیز دیگری خواهد بود.
اما زمانی فرا خواهد رسید که نیاز به دسترسی باید در بازه زمانی طولانیمدتی تضمین شود. برای مثال در یک بیمارستان باید برق دستگاههای حیاتی همواره (همان پنج تا 9 یا 99.999 درصد مواقع) تامین شود و در صورت رخ ندادن این امر، بهاحتمال زیاد شاهد ازدسترفتن زندگیهای زیادی خواهیم بود.
یا سیستمهای نظارتی امنیتی سرویسهای نظامی بهصورت مداوم باید آنلاین باشند و کار کنند. نمیتوان انتظار داشت که امنیت یک کشور و مردم آن به دلیل قطع سیستمهای نظامی به خطر افتد. موارد و مثالهای زیادی میتوان برای دسترسی سطح بالا (HA) ذکر کرد که در تیتر جداگانهای به بررسی مهمترین موارد آن خواهیم پرداخت. فقط بهتر است تا به اینجا معنی و مفهوم High availability را بهصورت کلی درک کنید تا در ادامه به بررسی دقیقتر آن بپردازیم.
نحوه طراحی سیستمهای High availability
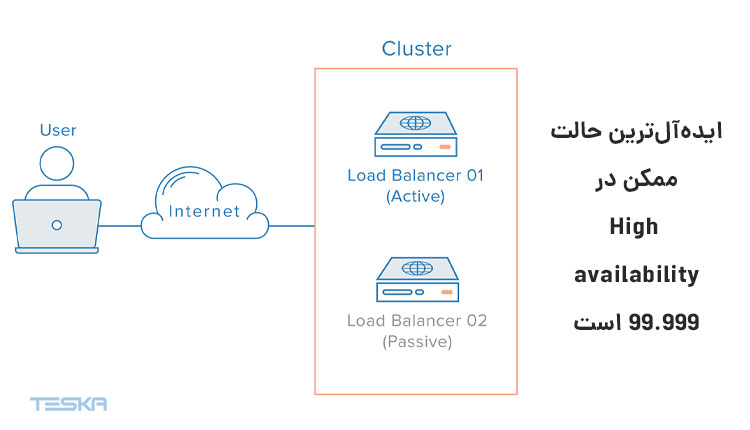
در دنیای آمار و احتمال و ریاضی چیزی به اسم 100 درصد وجود ندارد. نمیتوان انتظار داشت که در صددرصد مواقع حالتی مطلوبی رخ دهد. نمیتوان تصور کرد که حتی یک ماشین تمامی وظایف خود را در 100 در 100 زمان بهخوبی انجام دهد. غیرممکن است که در سیستم و سرویسی نمره 100 از 100 را در عملکرد آن ثبت کرد. مطلوبترین حالت ممکن، نزدیکترین عدد ممکن به صد خواهد بود که در High availability این عدد 99.999 است.
یعنی در دسترسیهای سطح بالا انتظار میرود که بهاحتمال 1 هزارم امکان ازدسترفتن دسترسی وجود دارد. این رقم قابلقبول و حتی بسیار مطلوب بوده و تا میزان زیادی اطمینان و اعتماد به یک service را برآورده میسازد. اما برای رسیدن به آن، باید 3 نکته مهم و اساسی را در طراحی سیستمهای HA در نظر داشت:
- نبود نقاط شکست یکتا
- crossover (معبر) قابلاعتماد
- تشخیص شکست
نبود نقاط شکست یکتا
منظور از نقاط شکست، اجزاء مختلفی از سیستمها و سرویسها بوده که در صورت خرابی و ازدستدادن آنها، کل سیستم سرویس از دسترس خارج خواهد شد. حال در طراحی سیستمهای دسترسی بالا باید این نکته مهم را در نظر داشت که در کل سیستم نباید حتی یک نقطه شکست تنها وجود داشته باشد. یعنی اجزائی که نقطه شکست محسوب میشوند، حداقل باید 2 عدد از آنها وجود داشته باشد.
برای مثال در شبکه (network) سازمانها و شرکتها، سرور یک نقطه شکست است. زیرا در صورت خرابی آن نتورکی وجود نخواهد داشت. ازاینرو در طراحی High availability یک شبکه باید از 2 سرور (حداقل) استفاده کرد تا ریسک ازدسترفتن سیستم کاهش یابد.
Crossover معبر قابلاعتماد
معبر یا crossover مولفهای است که بهعنوان راهحل پشتیبان از آن یاد میشود. مانند استفاده از Y بهجای X برای جلوگیری از آفلاین شدن سرویس یا سیستم در زمانی که X را از دست دهیم. برای مثال میتوان نیروی برق پشتیبان را همان crossover یا معبر یادکرد که قابلاعتماد نیز است. یعنی زمانی که بر اثر هر اتفاقی مثلا برق بیمارستان قطع شود، بلافاصله برق اضطراری وصل شده تا از دسترس خارجشدن دستگاههای حیاتی جلوگیری شود.
حالتهای مختلفی که ممکن است رخ دهد باید بهصورت دقیق و ریزبهریز بررسی شود تا بتوان برای هرکدام از آنها crossover مناسبی در نظر گرفت. در موارد نظامی ممکن است استفاده از سیستمهای آنالوگ در هنگام قطع امواج دیجیتال بهعنوان معبری مطمئن در دستور کار قرار گیرد. حالتهای متفاوتی در صنایع مختلف ممکن است برای رسیدن به High availability وجود داشته باشد.
تشخیص شکست
دو نکته بالا برای جلوگیری از قطع دسترسی کامل سرویسها در زمان شکست اجزاء بودند، درحالیکه تشخیص شکست، بیشتر بهمنظور بهبود عملکرد HA استفاده میشود. یعنی در یک سرویس و سیستم باید شکستها و خرابیها قابلمشاهده باشند تا هم بهسرعت تعمیر شوند و هم در آینده از وقوع دوباره آنها تاحدامکان جلوگیری کرد.
در حالت مطلوب سیستمها دارای اتوماسیون داخلی هستند تا بهصورت اتوماتیک بتوانند این شکستها و خرابیها را مدیریت کنند. این اتوماسیونها با شکستهای رایج نیز آشنا هستند و از وقوع اغلب آنها جلوگیری میکنند. مانند زمانی که یک یا چند سیستم و جزء به یک علت از کار میافتند.
برای اطمینان از تحقق High availability، علاوه بر سه نکته مهم و اساسی ذکر شده، استفاده از سیستم متعادلکننده بار نیز در طراحی دسترسی بالا لازم است. زمانی که کاربران زیادی از سرویس ارائه شده استفاده میکنند، نیاز است تا حجم بالای درخواستها دریافتی و پاسخهای ارسالی بر اساس منابع موجود متعادل شود.
به این صورت که متعادلکننده بار با اجرا در لایههای میانی شبکه سازمانها و صنایع مختلف تشخیص میدهد که بار موجود توسط کدام منابع به بهترین صورت مدیریت و هندل میشود و با توزیع مناسب آن عملکرد سیستم و منابع موجود را افزایش میدهد.
همچنین سرورها در HA بهصورت خوشهای طراحی میشوند. به دو دلیل؛ دلیل اول پاسخ مناسب به متعادلکنندههای بار برای توزیع مناسب درخواستها است. دلیل دوم جایگذاری سرورهای پشتیبان در صورت ازدستدادن سرور در سریعترین زمان ممکن و با کمترین تاثیر بر عملکرد سیستم است. هر چه سیستم و سرویسی پیچیدهتر باشد طراحی HA در آن سختتر خواهد بود.
مثالهایی از استفاده High availability در صنایع مختلف
به استفاده از سیستمهای مختلف دسترسی بالا در صنایع نظامی و پزشکی اشاره شد ولی High availability تنها به این موارد محدود نمیشود.
- مطمئناً با شرکت تسلا آشنا هستید که تولیدکننده خودروهای هوشمند با مدیریت ایلان ماسک، ثروتمندترین مرد دنیا در سال 2022، است. این خودروها قابلیت خودران و رانندگی اتوماتیک را دارند که استفاده از سیستم HA باید با درصد بالا (یعنی 99.999) صورت گیرد. زیرا یک خطا و قطع دسترسی میتوان به قیمت جان انسانها تمام شود.
- سرویسهای ابری یا Cloud service مثال دیگر استفاده از دسترسی بالا است. سرویسهای ابری ارائهدهنده خدمات به میلیونها کاربر هستند که یک اشکال و قطع دسترسی میتواند منجر به واردشدن میلیونها دلار خسارت به شرکت شود. همچنین اعتماد و اعتبار شرکتهای ارائهدهنده خدمات ابری متکی به HA است و رابطه مستقیمی با آن دارد.
- شبکههای بزرگ مانند سایتهایی با تعداد کاربران بالا از دیگر سرویسهایی هستند که باید از سیستمهای High availability استفاده کنند. زیرا در طول شبانهروز ممکن است تعداد کاربران استفادهکننده از آنها تغییر کند که در نتیجه با اجرای یک سیستم مناسب از دسترسی بالا، میتوان در مواقع مختلف از منابع مناسب استفاده کرد.
- صنایع هوایی نیز همانند موارد دیگر از جمله حوزههایی است که سیستمهای دسترسی بالا در آنها بهصورت ویژهای اجرا میشود. برای مثال در بخش کنترل پرواز در صورت ایجاد اشکال در قسمتی از شبکه ممکن از تا کل سیستم از دسترسی خارج شود و در نهایت جان چند صد مسافر به خطر بیفتد.
تقریبا در هر زمینهای که حساسیتهای بالایی در اجرا و عملکرد شبکه توافق شده باشد، نیاز به HA حس خواهد شد. موارد بالا از جمله بارزترین صنایع و حوزههایی بودند که تا میزان زیادی برای بقا به سیستمهای HA متکی هستند.

محاسبه میزان High availability
مقدار دسترسی بالا را میتوان نسبت به 100 درصد (سیستم و سرویسی که هیچوقت خراب نمیشود یا از دسترس خارج نمیشود) محاسبه و اندازهگیری کرد. قاعده کلی برای محاسبه High availability بهصورت زیر است.
دردسترسبودن = (دقیقه در یک ماه – دقیقه ازکارافتادگی) * 100/دقیقه در ماه
معیارهای استفاده شده در محاسبه مقدار دردسترسبودن شامل:
- MTBF: Mean time between failures میانگین زمان بین شکستها، به این معنی که چقدر طول میکشد تا بعد از یک شکست و از دسترس خارجشدن سیستم یا سرویس، شکست دیگری رخ دهد.
- MDT: Mean downtime میانگین زمان خرابی یا شکست، یعنی هر خرابی بهصورت متوسط چقدر طول میکشد و بازه زمانی هر شکست چهقدر در نظر گرفته میشود.
- RTO: Recovery time objective زمان واقعگرایانه برای بازیابی، نشاندهنده تخمین بازه زمانی موردنیاز برای تعمیر و بازیابی یک قطع دسترسی از پیش تعیین شده یا پیشبینی نشده بهصورت معقول است.
این معیارها را میتوان در SLA یا service-level agreement به کاربرد. منظور از SLA قرار دادهایی هستند که در آنها درصد و میزان دردسترسبودن خدمات یا سیستمی مشخص میشود. در مواردی ممکن است یک service تا حد زیادی به عملکرد خود ادامه دهد ولی کاربران نتوانند به آن دسترسی پیدا کنند. در این موقع نیاز است تا اهداف و انتظارات از High availability بهصورت صریح ذکر شده و همچنین این موارد در SLA مستند شوند.
اگر در قرارداد SLA شما درصد 99.999 برای HA درج شده باشد، بر اساس دادههای جدول زیر میتوانید انتظار قطع شدن سیستم یا سرویس خود در بازههای زمانی مختلف را داشته باشد.
| بازه زمانی | زمان از دسترس خارجشدن |
| روزانه | 0.9 ثانیه |
| هفتگی | 6 ثانیه |
| ماهانه | 26.3 ثانیه |
| سالانه | 5 دقیقه و 15.6 ثانیه |
اگر بازه زمانی سالانه را در نظر بگیریم و عدد درج شده در SLA نیز 99.9 باشد، مدیران صنایع و شرکتهای مختلف باید انتظار قطع شدن سیستمهای خود را به مدت 8 ساعت و 45 دقیقه داشته باشند و در صورت درج شدن 99 درصد، این میزان تا بیش از 3 روز در سال نیز افزایش مییابد که تفاوت چشمگیری با ارقام قبلی دارد.
چگونه دسترسی بالا (HA) پیادهسازی میشود؟
برای پیادهسازی HA پیمودن 6 پله زیر کافی خواهد بود:
پله اول: طراحی سیستم با درنظرگرفتن High availability. برای طراحی سیستمی با دسترسی بالا باید اهداف ذکر شده در قرارداد با کمترین هزینه و پیچیدگی اجرا شده و در صورت وجود نقطه شکست از افزونگی (همان Y بهجای X) استفاده شود.
پله دوم: تعریف معیارهای موفقیت و عملکرد مورد انتظار. ارائهدهندگان خدمات مربوطه با استفاده از SLA به مشارکت با مشتریان برای تعیین سطح دسترسی و میزان انتظارات برای عملکردی که ارائه خواهد شد، میپردازند.
پله سوم: استقرار سختافزار. در پله سوم باید منابع سختافزاری بر اساس دو معیار مقرونبهصرفه بودن و کیفیت موردنیاز، تهیه و مستقر شوند. منابع باید انعطافپذیر و بر اساس نیازها سازمان متعادل شود تا اجرای HA به بهترین شکل ممکن صورت گیرد. پیشنهاد میکنیم تا از سختافزارهایی که هنگام تعویض یا قطع شدن از شبکه نیازی به خاموشکردن آنها نیست، استفاده کنید.
پله چهارم: تست سیستم اجرا شده. بعد از طیکردن سه مرحله قبلی حال باید سیستم اجرا شده تست شود تا از عملکرد درست آن اطمینان حاصل شود. همچنین در بازههای زمانی مقرر شده باید آزمایشها دوباره و دوباره در یک برنامه مناسب تکرار شوند.
پله پنجم: رصد سیستم High availability. بهصورت مداوم و مستمر باید سیستم مانیتورینگ شده تا در هنگام وقوع رخداد پیشبینی نشده، دادههای آن ثبت و نسبت به تنظیمات موردنیاز برای رفع آن اقدام شود.
مطالعه مقاله مانیتورینگ شبکه چیست؟ را پیشنهاد می کنیم.
پله ششم: ارزیابی دادهها. با ارزیابی دادههای بهدستآمده میتوان نسبت به بهبود عملکرد سیستم HA اقدام کرد و اعتماد به آن را در شرایط مختلف بالا برد.
جمعبندی
دسترسی بالا (High availability که مخفف آن HA است) سیستمی برای اطمینان از عملکرد مناسب و مورد انتظار از یک سرویس در بازه زمانی معین بوده که در صنایع مختلف و حساسی مانند نظامی و درمانی کاربرد دارد. یکی از بارزترین مثالهای High availability سیستم خودران اتومبیلها است. در این وسایل نقلیه باید انتظار داشت تا سرویس ارائه شده برای حداقل 8 ساعت بدون هیچ خطا و افت عملکردی به کار خود ادامه دهد.
میزان حساسیت در همین ماشینهای هوشمند یا صنایع پزشکی و نظامی بسیار بالا بوده زیرا صحبت از جان انسانها در میان است. در این مقاله سعی شده تا به بررسی کامل و جامع HA همراه با مثالهایی برای تفهیم بهتر آن بپردازیم. امید است تا مطالعه آن برای کاربران عزیز مفید باشد.










دیدگاهتان را بنویسید